


チュートリアルの内容
今回は、時系列予測のためのLSTMを使用する方法を説明します。今回は簡単な「株価予測」を例に取り、LSTMを実際に実行してみます。
データセットの準備
今回は、yfinanceライブラリを使用して、Yahoo Financeから株価データを取得します。まず、yfinanceをインストールします。
pip install yfinance次に以下のコードで株価データを取得します。
import yfinance as yf
import pandas as pd
# 例としてAppleの株価データを取得
ticker = 'AAPL' # Appleのティッカーシンボル
data = yf.download(ticker, start='2015-01-01', end='2023-12-01')
# 株価データを表示
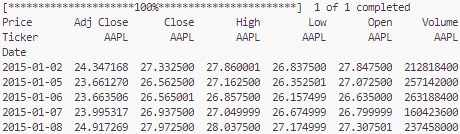
print(data.head())以下が実行結果です。これで、Apple(AAPL)の株価データが取得できました。データには、Open, High, Low, Close, Adj Close, Volumeの情報が含まれていますが、今回はClose(終値)のみを使用します。
データの前処理
LSTMモデルにデータを適用する前に、いくつかの前処理を行います。特に、LSTMに入力するためには、データを正規化(スケーリング)する必要があります。また、モデルの入力形式に合わせるために、時系列データを適切に分割します。
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# 'Close'列だけを使用
close_data = data['Close'].values.reshape(-1, 1)
# 正規化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(close_data)
# データを訓練用とテスト用に分割
train_size = int(len(scaled_data) * 0.8)
train_data = scaled_data[:train_size]
test_data = scaled_data[train_size:]
# 時系列データをLSTMの入力形式に変換
def create_dataset(data, time_step=60):
X, y = [], []
for i in range(len(data) - time_step - 1):
X.append(data[i:(i + time_step), 0])
y.append(data[i + time_step, 0])
return np.array(X), np.array(y)
# 訓練データとテストデータを作成
time_step = 60 # 60日分のデータを使用
X_train, y_train = create_dataset(train_data, time_step)
X_test, y_test = create_dataset(test_data, time_step)
# 入力データの形状をLSTMに合わせる
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
print(X_train.shape, X_test.shape)以下が実行結果です。
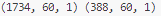
モデルの構築
次に、LSTMモデルを構築します。Keras(TensorFlow内の高水準API)を使って、LSTM層を追加します。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
# LSTMモデルの構築
model = Sequential()
# LSTM層を追加(50ユニット、シーケンシャルなデータ)
model.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1], 1)))
model.add(Dropout(0.2)) # 過学習防止のためのDropout層
model.add(LSTM(units=50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(units=1)) # 出力層(予測値)
# モデルをコンパイル
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルの要約を表示
model.summary()以下が実行結果です。

モデルの訓練
今回は、訓練データとして、株価データの80%を使用します。
# モデルを訓練
history = model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 訓練の結果を表示
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()
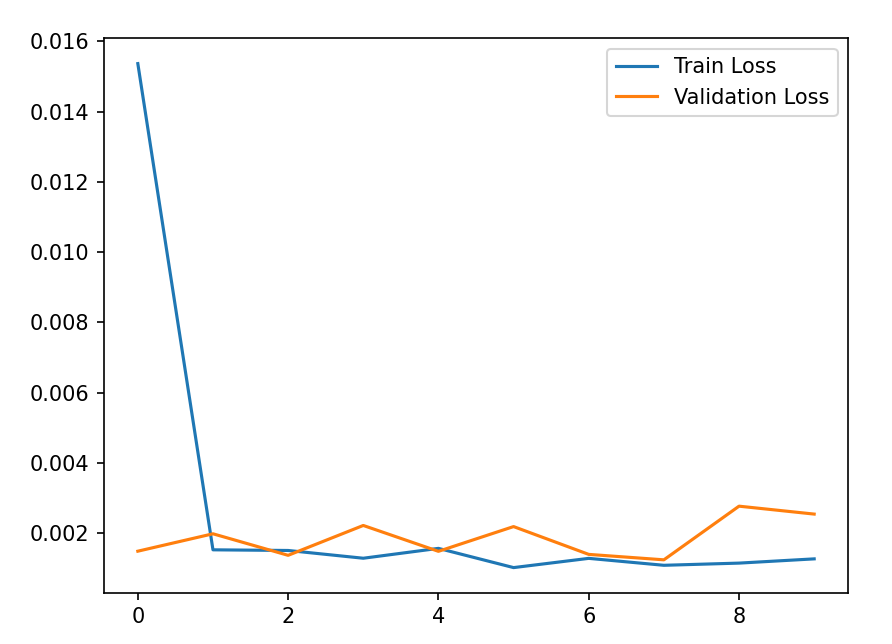
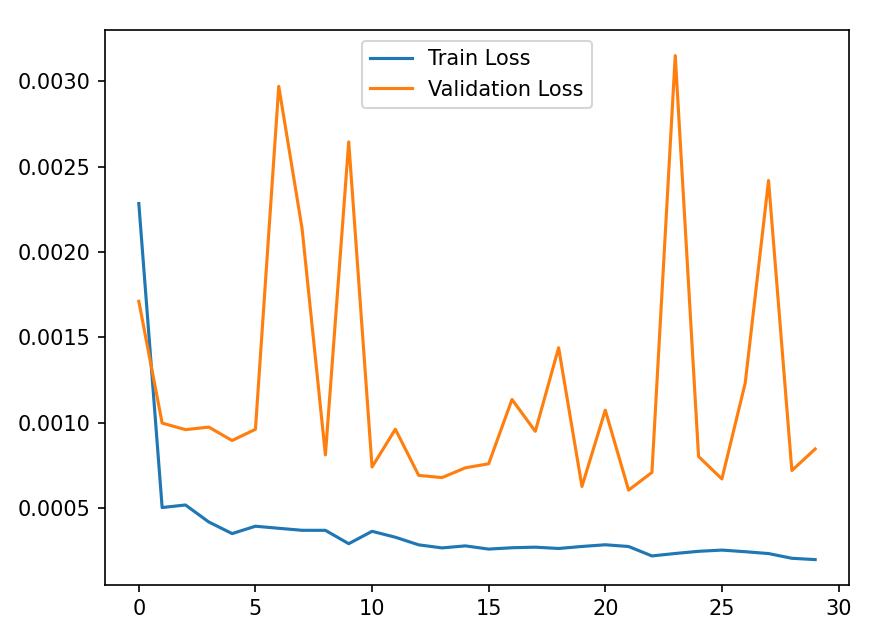
plt.show()Train Lossは訓練損失であり、訓練データに対する損失です。モデルが訓練データでどれだけ適切に動作しているかを示します。
Validation Lossは検証損失であり、テストデータに対する損失です。モデルが新しいデータに対してどれだけ一般化できているかを示します。
訓練損失が低くても検証損失が高い場合、過学習の可能性があります。
訓練損失と検証損失の両方が減少する場合、モデルが正しく学習しています。
評価と予測
評価データとして、株価データの20%を使います。
# テストデータで予測
predictions = model.predict(X_test)
# 予測結果を逆正規化
predictions = scaler.inverse_transform(predictions)
y_test_actual = scaler.inverse_transform(y_test.reshape(-1, 1))
# 結果を可視化
plt.plot(y_test_actual, color='blue', label='Actual Stock Price')
plt.plot(predictions, color='red', label='Predicted Stock Price')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
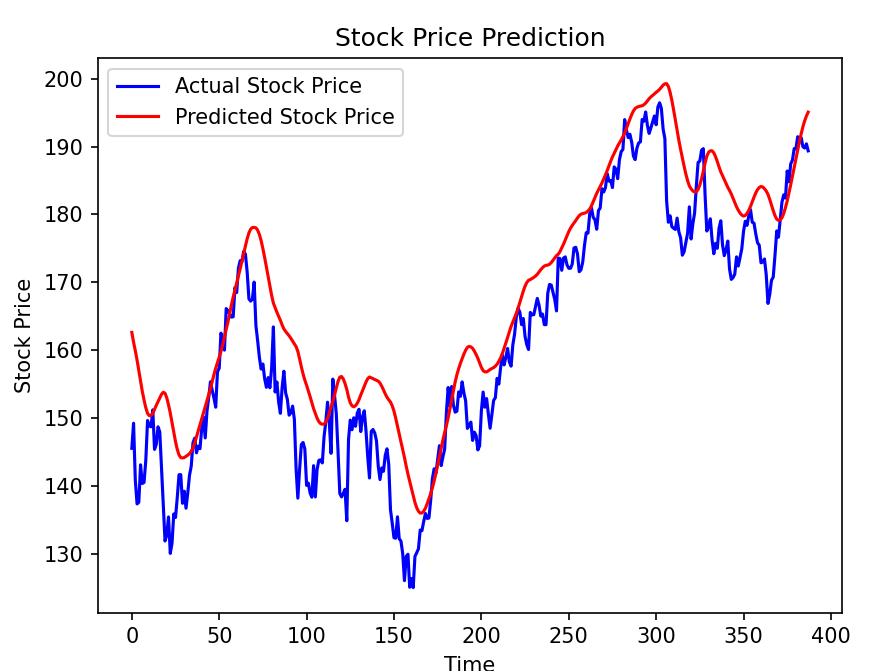
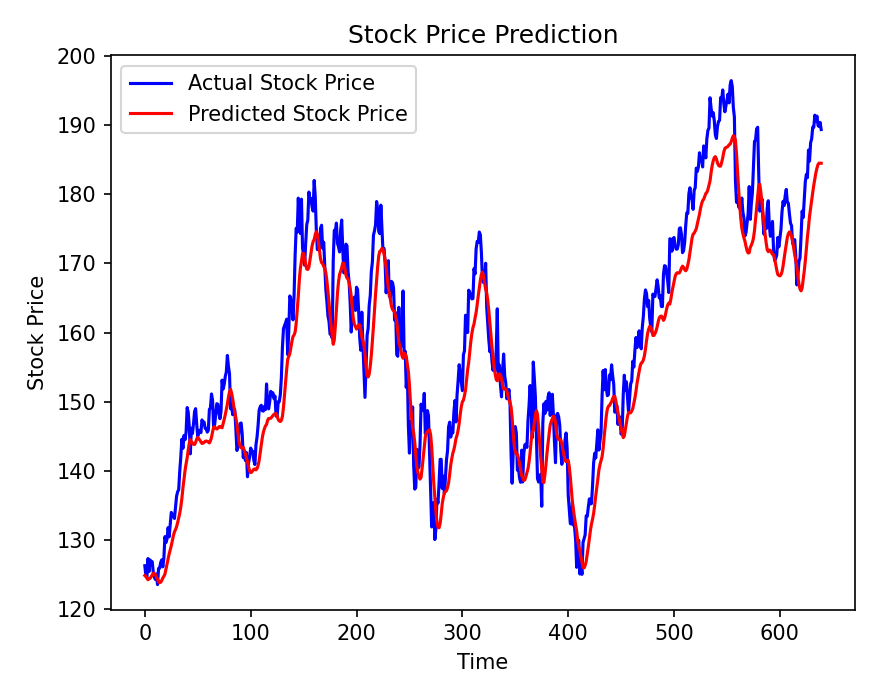
plt.show()テストデータを使用して、モデルの予測値と実際の値を比較します。この可視化により、モデルがどれだけ現実的なパターンを捉えているかを確認できます。
実際の値と予測値が近ければ近いほど、モデルが正確に予測していると言えます。
特に大きなトレンド(上昇や下降)が正確に予測されているかに注目すべきです。
RNNとの比較
LSTMは、RNNの長期的な依存関係に対応しづらいという問題点を解決するために開発されたモデルなので、比較してみます。先ほどよりもデータ数を増やして長期的な依存関係に見ます。
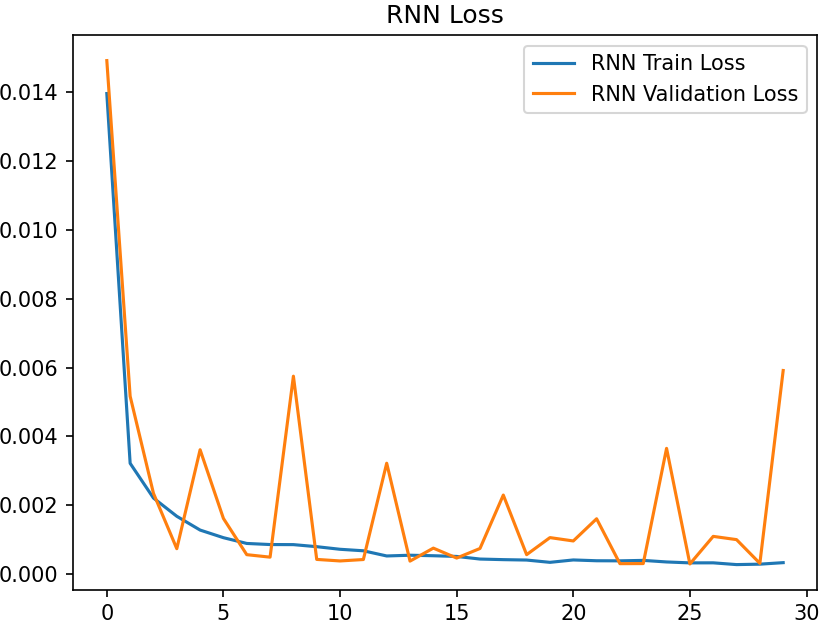
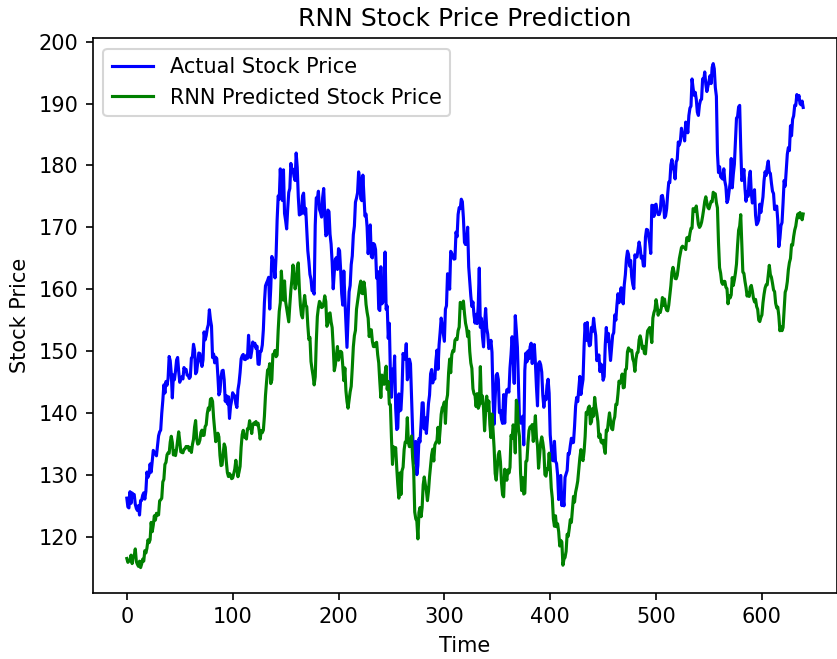
この結果から、LSTMはRNNより長期的な依存関係を持つデータに対する予測の精度が高いことが分かります。
まとめ
LSTMは計算コストが高いものの、長期的な依存関係を扱うのが得意で、時系列予測や自然言語処理などの複雑なタスクに適しています。RNNとLSTMを比較することで、タスクに応じてどちらのモデルを選ぶべきかを判断できるようになります。
このサイトでは、ITに関する記事を投稿しています。ぜひ他の記事もご覧ください。

